Vega: Replacing a third-party dependency with an AI-native product master
Overview
Problem
Every GP Vega onboards today inherits the same requirement: static fund data has to come from somewhere, and right now that somewhere is Daphne. That means Vega cannot bring on a new GP without also bringing Daphne into the relationship, a third party providing a capability that sits at the center of the platform.
This creates two compounding issues. First, it caps how fast Vega can grow, since onboarding speed is bound by a partner Vega doesn't control. Second, it leaves a core piece of the product outside Vega's own roadmap, making it harder to improve reliability, self-service, or data model design on Vega's own timeline.
Scope note: the fix is not to compete with Daphne or productize this as a standalone offering with external APIs. It's to remove the dependency for Vega's own onboarding pipeline.
Solution
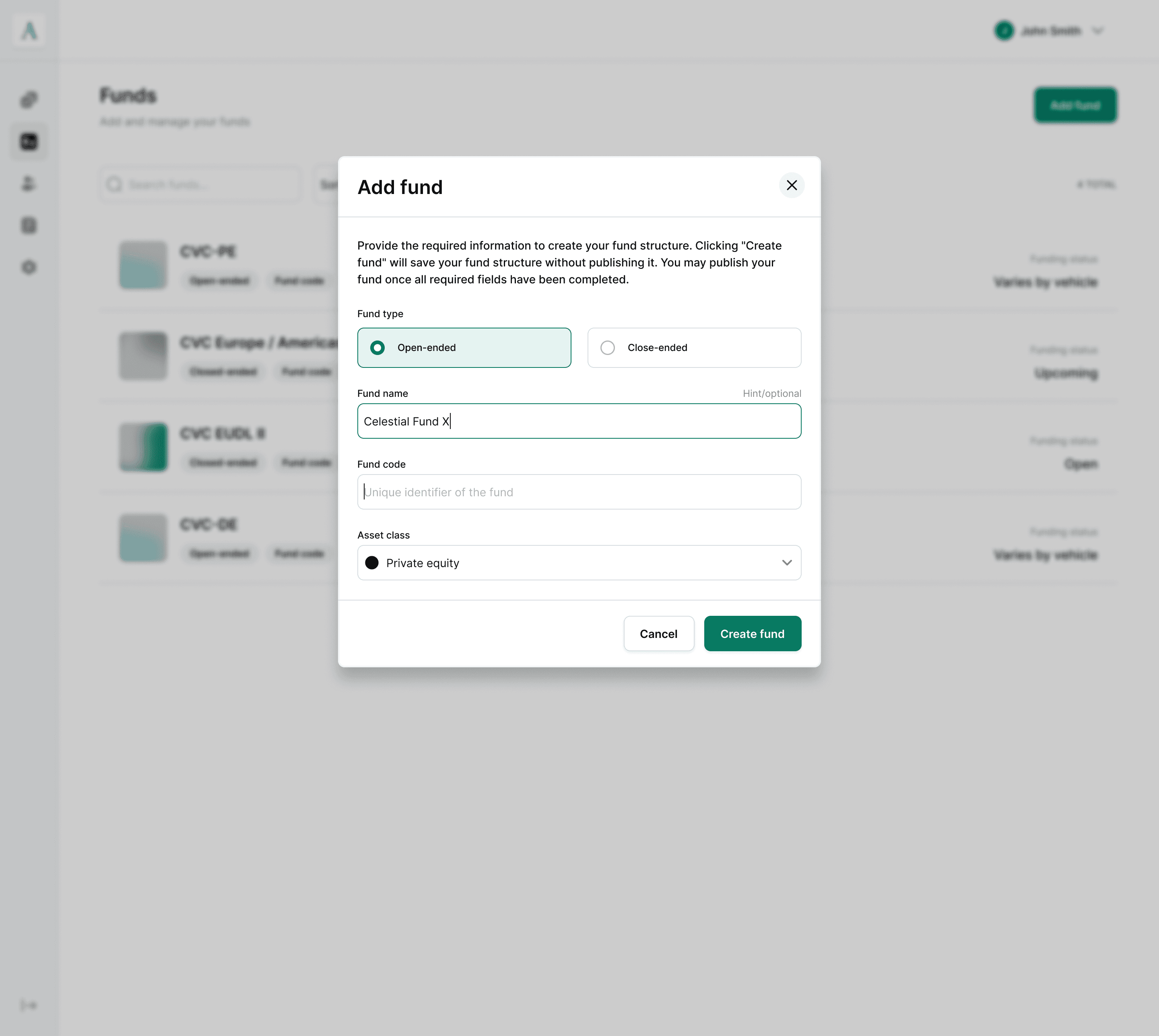
Vega is building an AI-native product master, designed around a simple pipeline: ingest → review → publish.
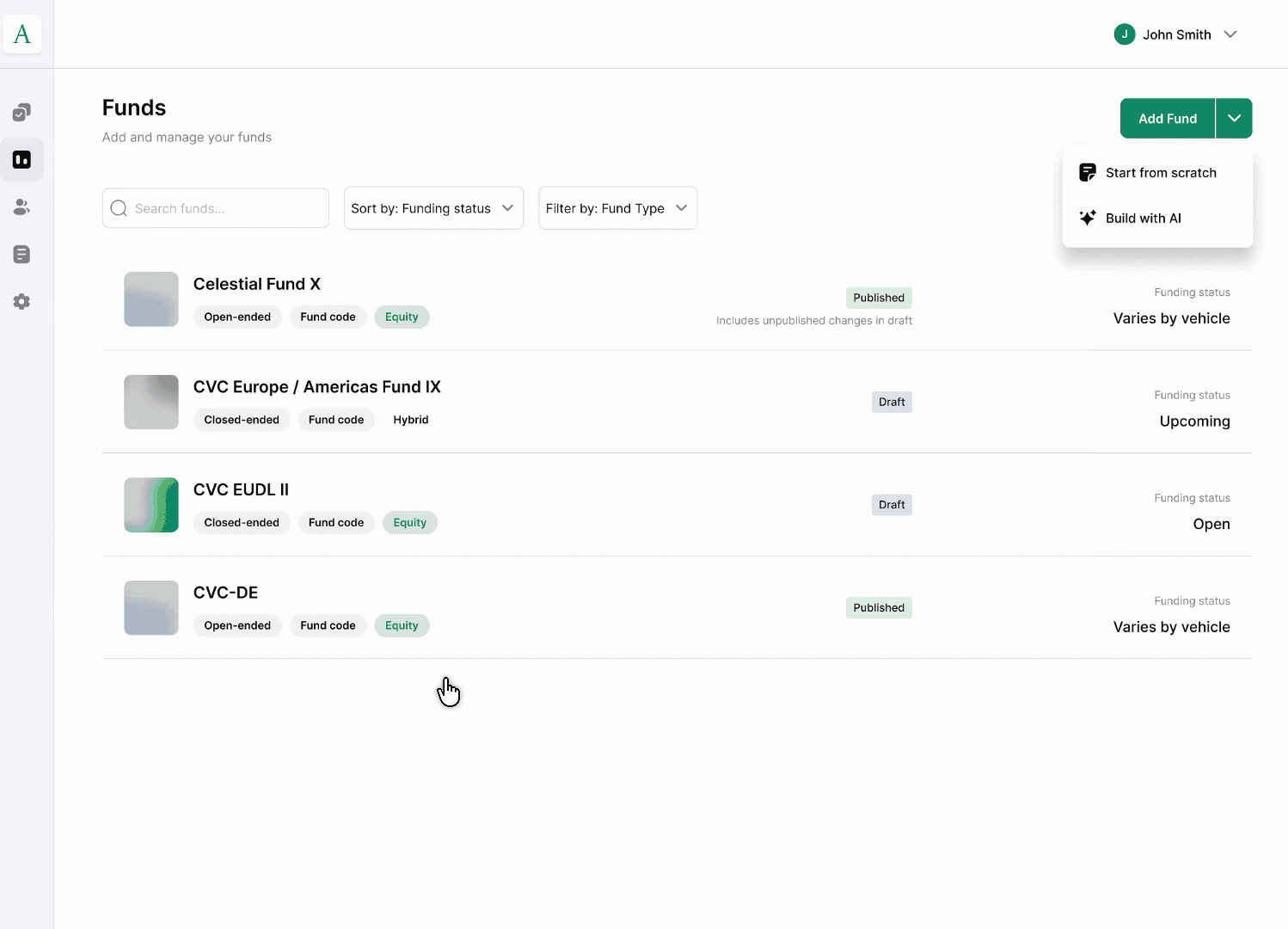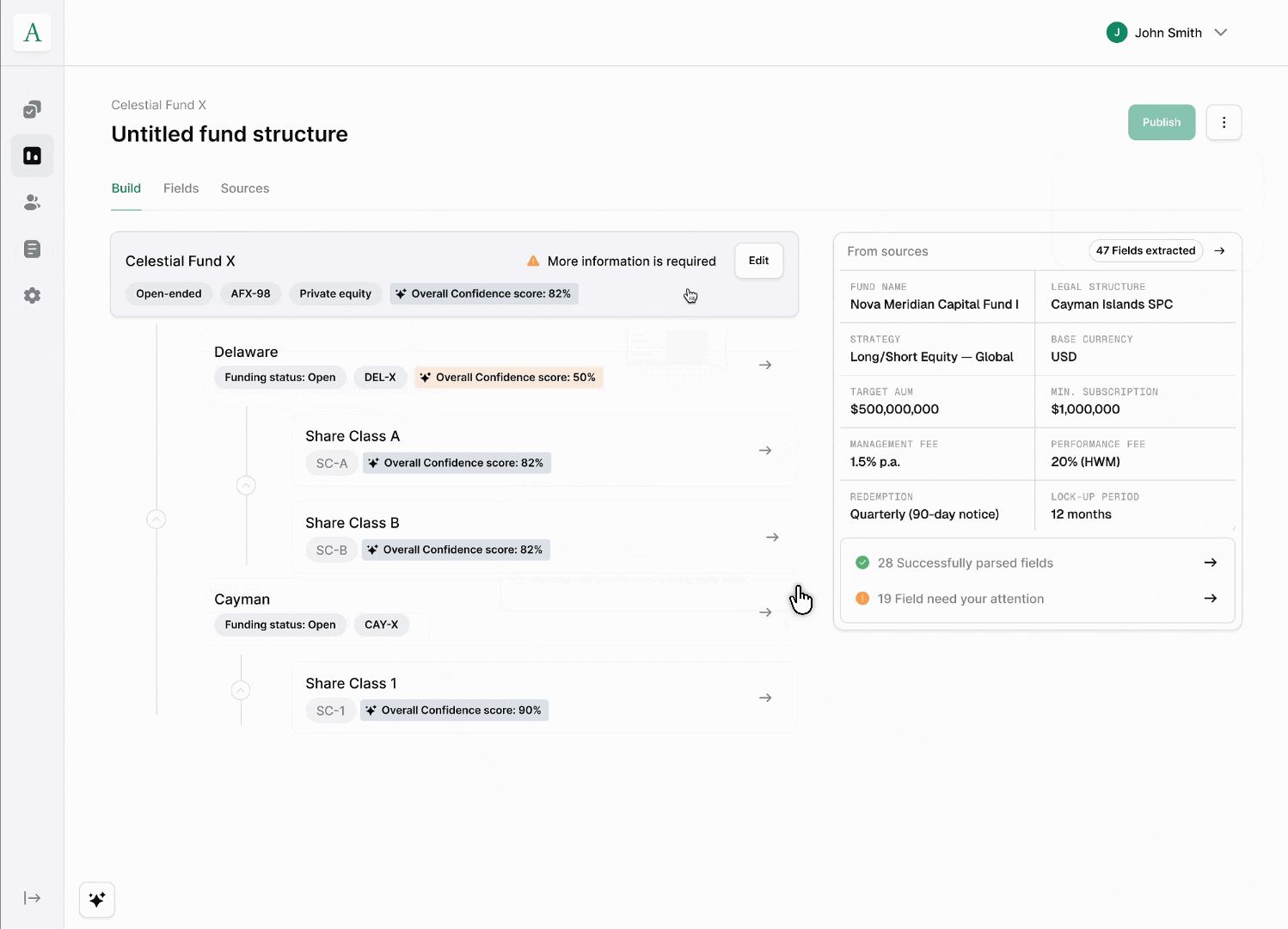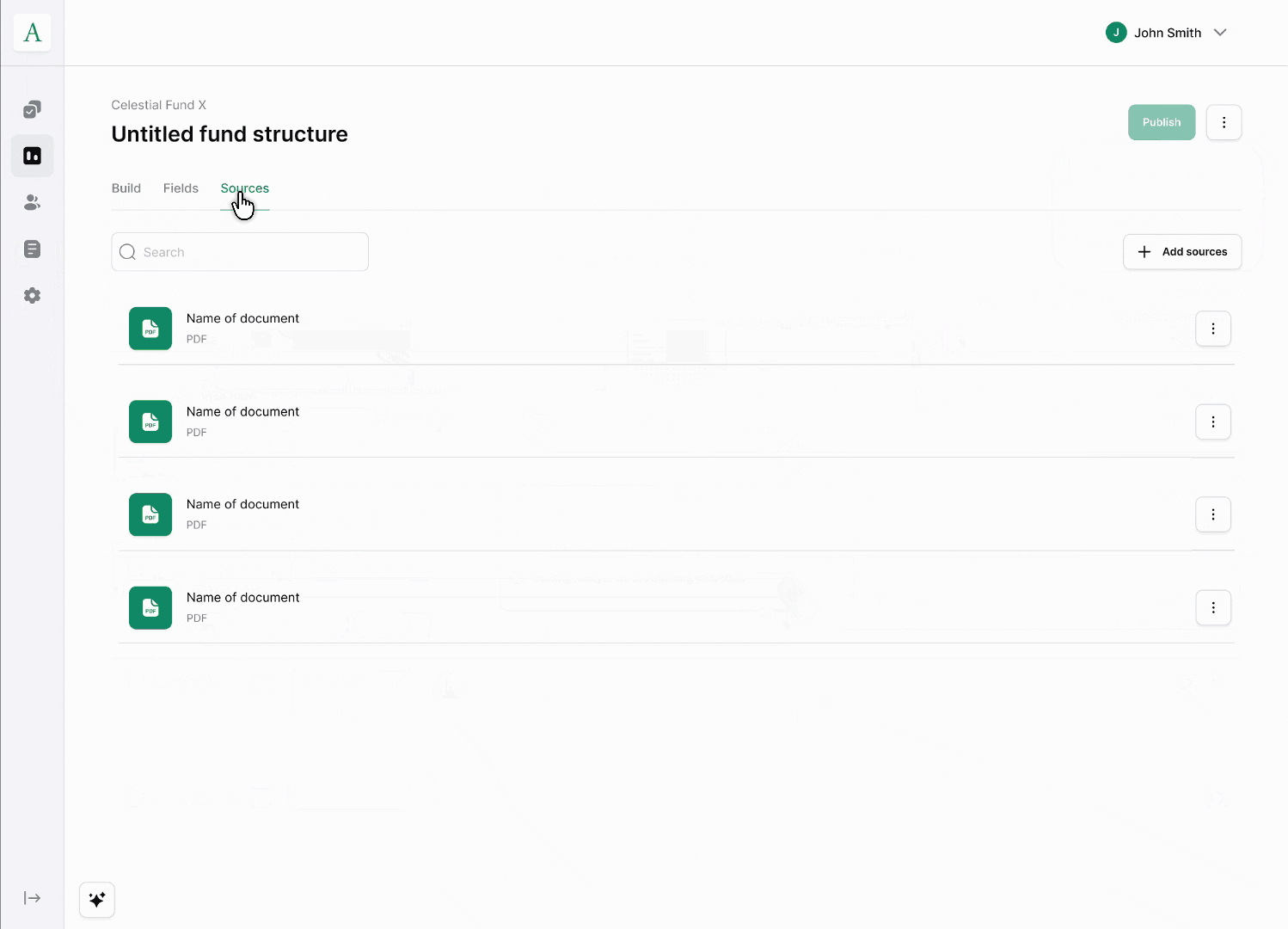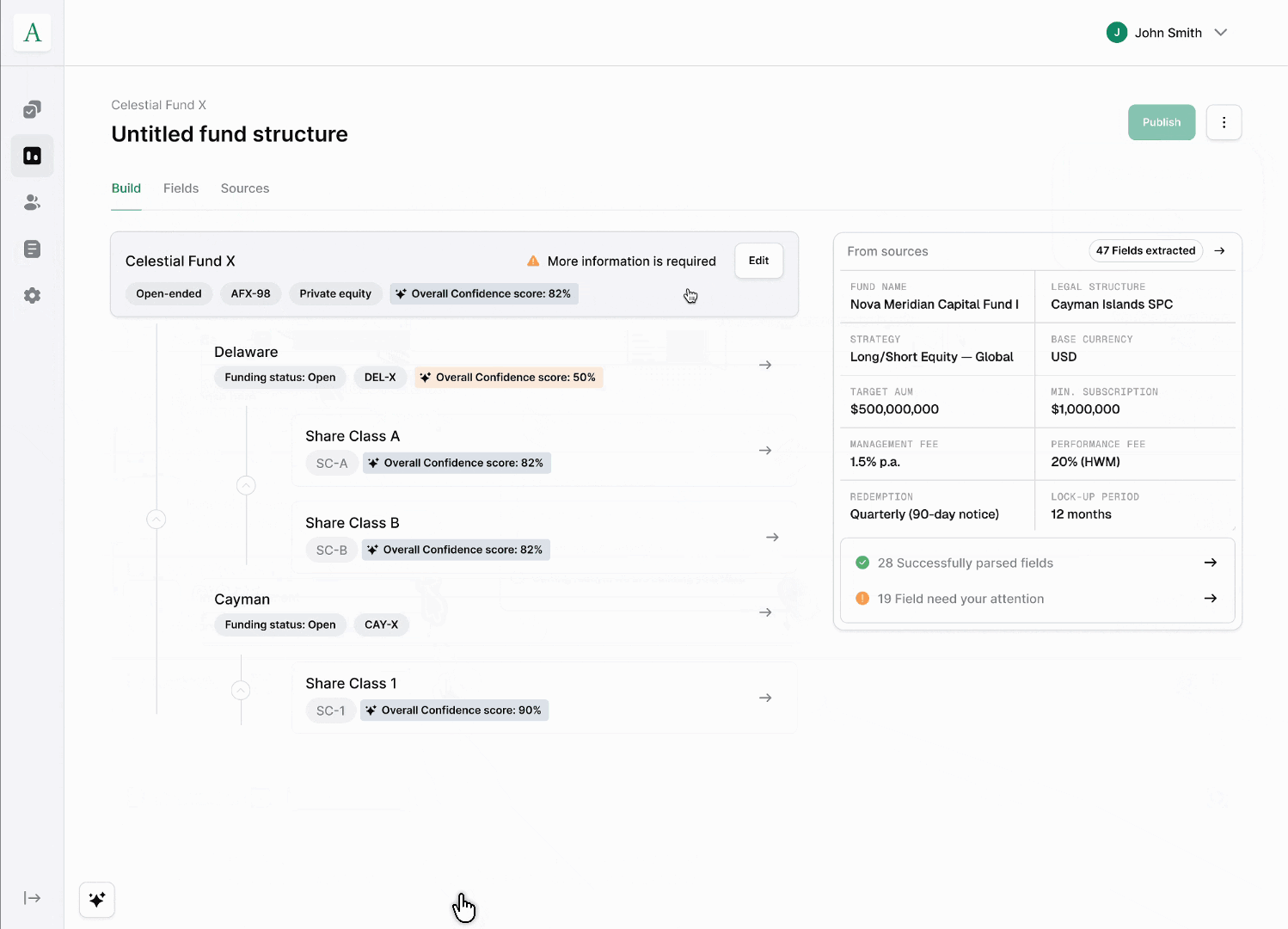
Ingestion. GPs bring in fund data as-is (documents, spreadsheets, existing records) rather than filling out forms field by field. The system parses the fund → vehicle → share class hierarchy directly from what's submitted.
Review parsed fields. GPs check and correct the parsed output before anything goes live, so the workflow stays self-service without sacrificing accuracy. This is the checkpoint that makes AI-assisted ingestion trustworthy rather than a black box.
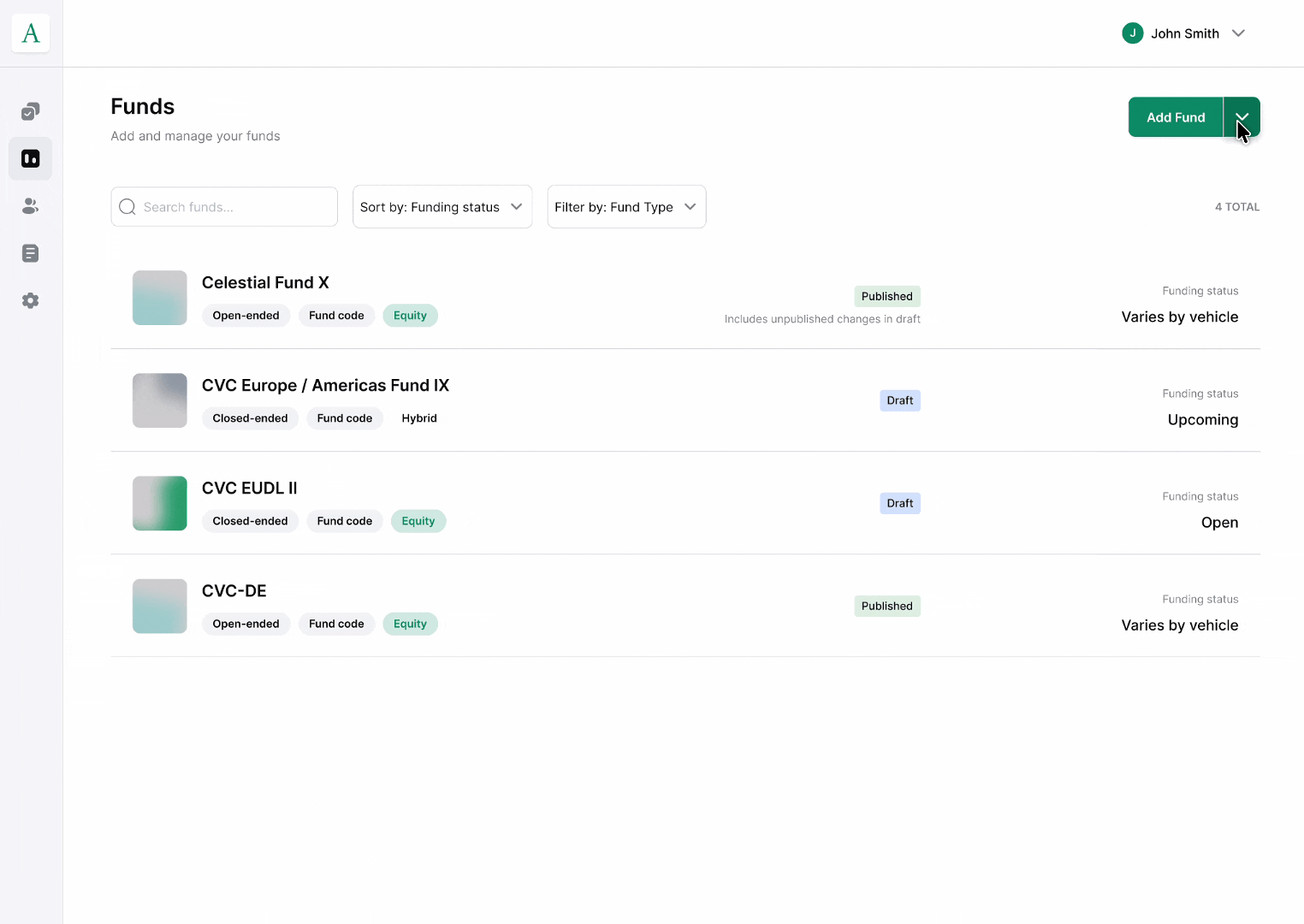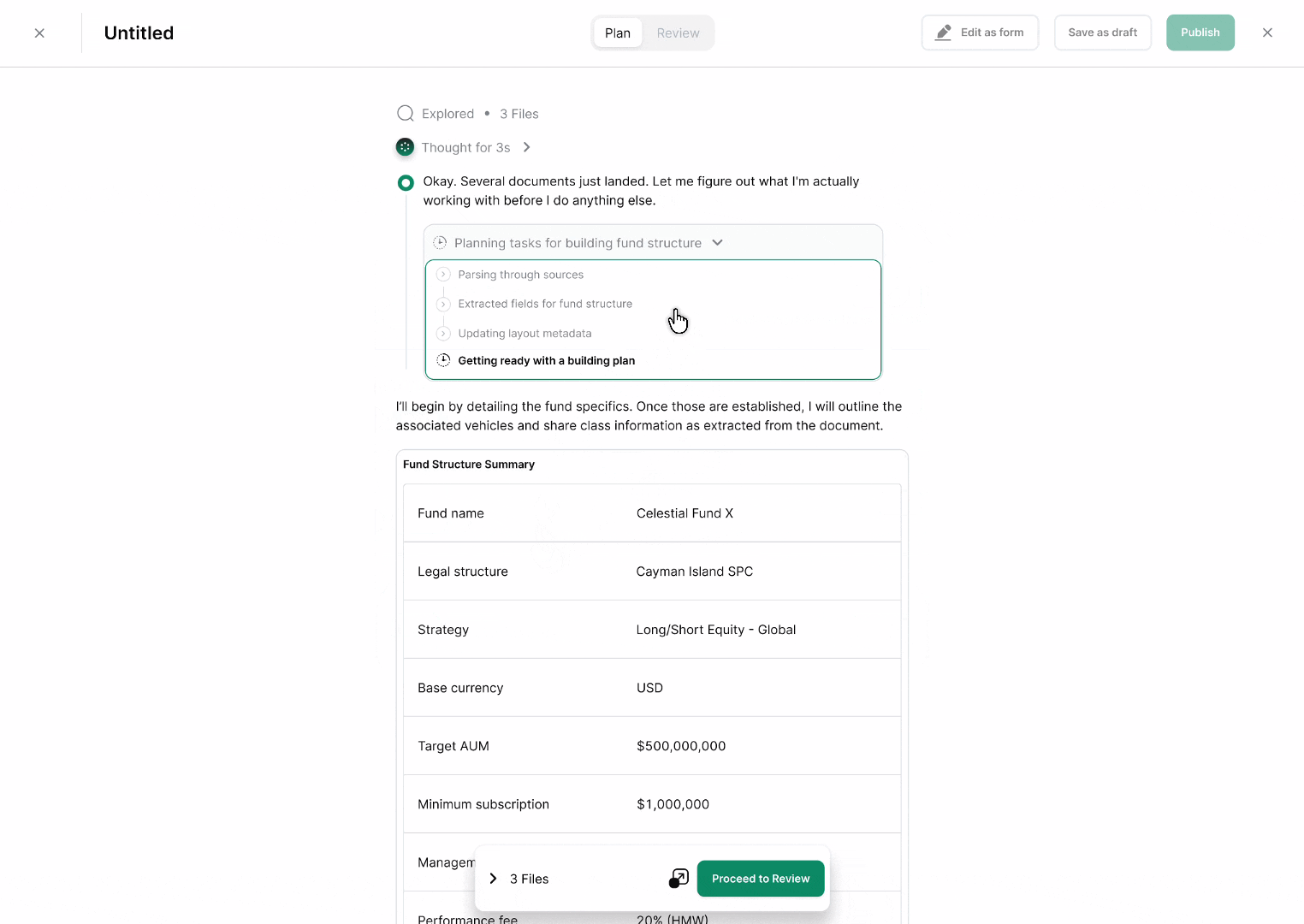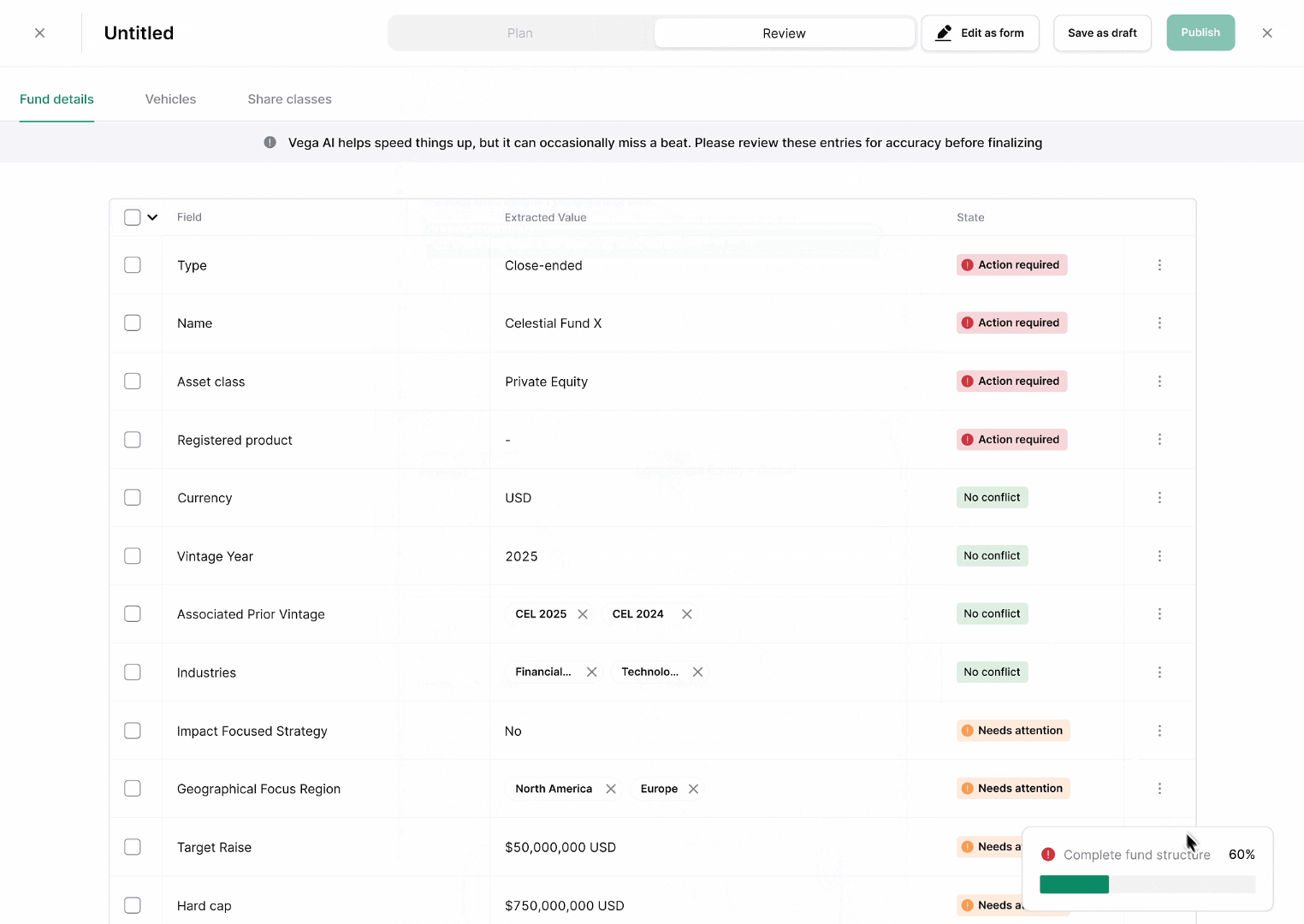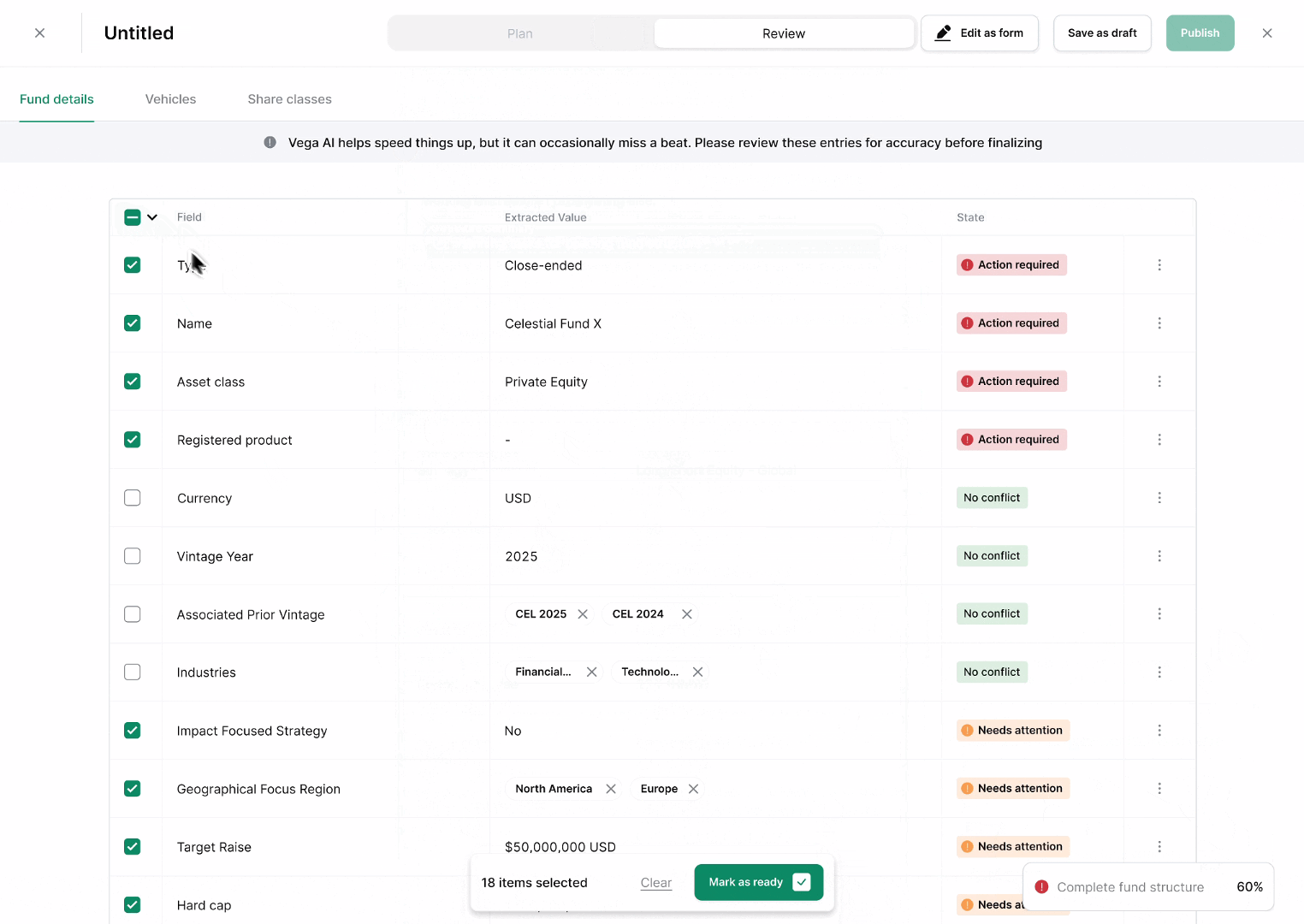
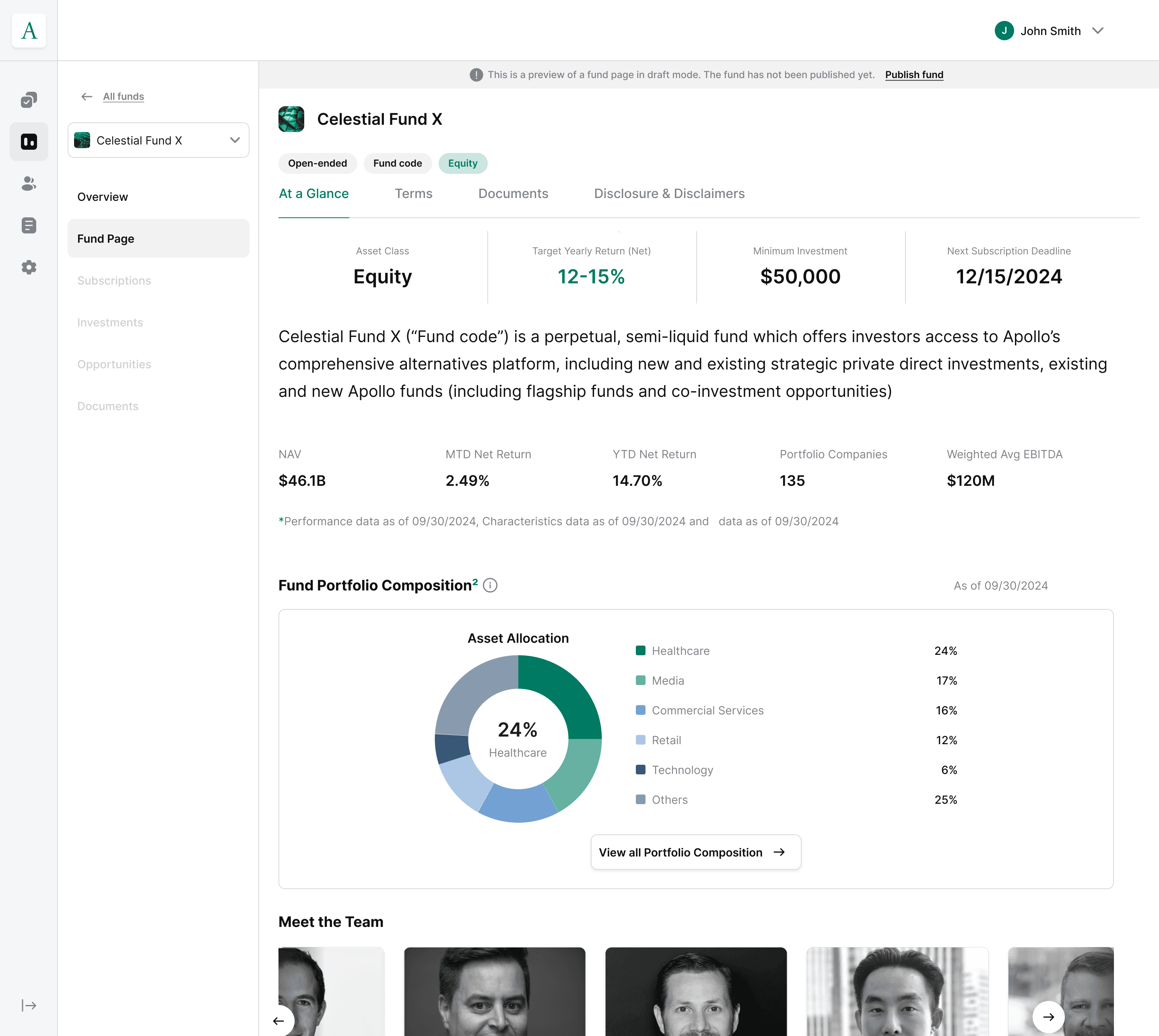
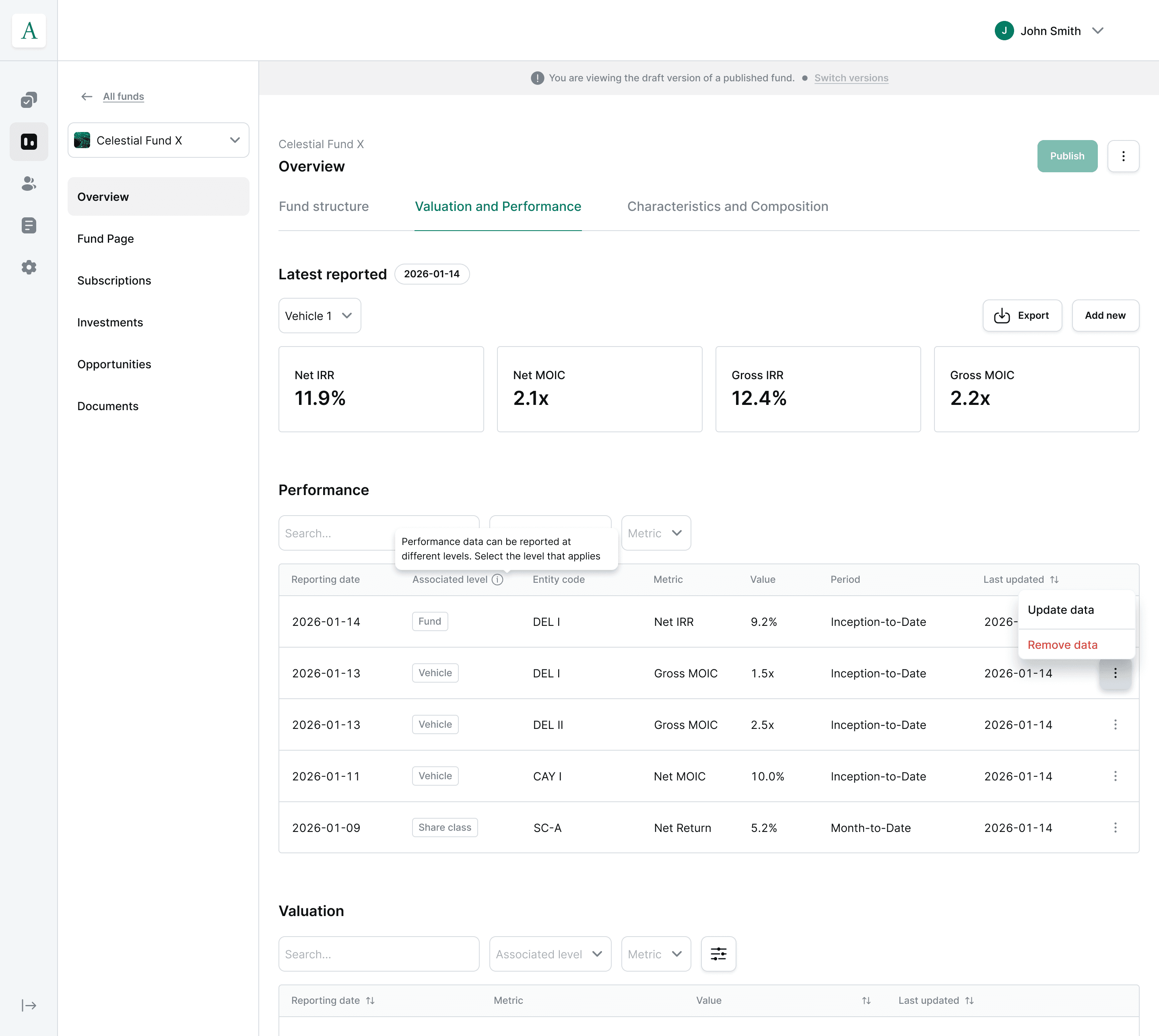
Publish fund. Once reviewed, fund data is published and immediately usable by downstream services (offering pages, subscriptions, reporting) with no manual re-entry step.
This pipeline is built around three additional principles:
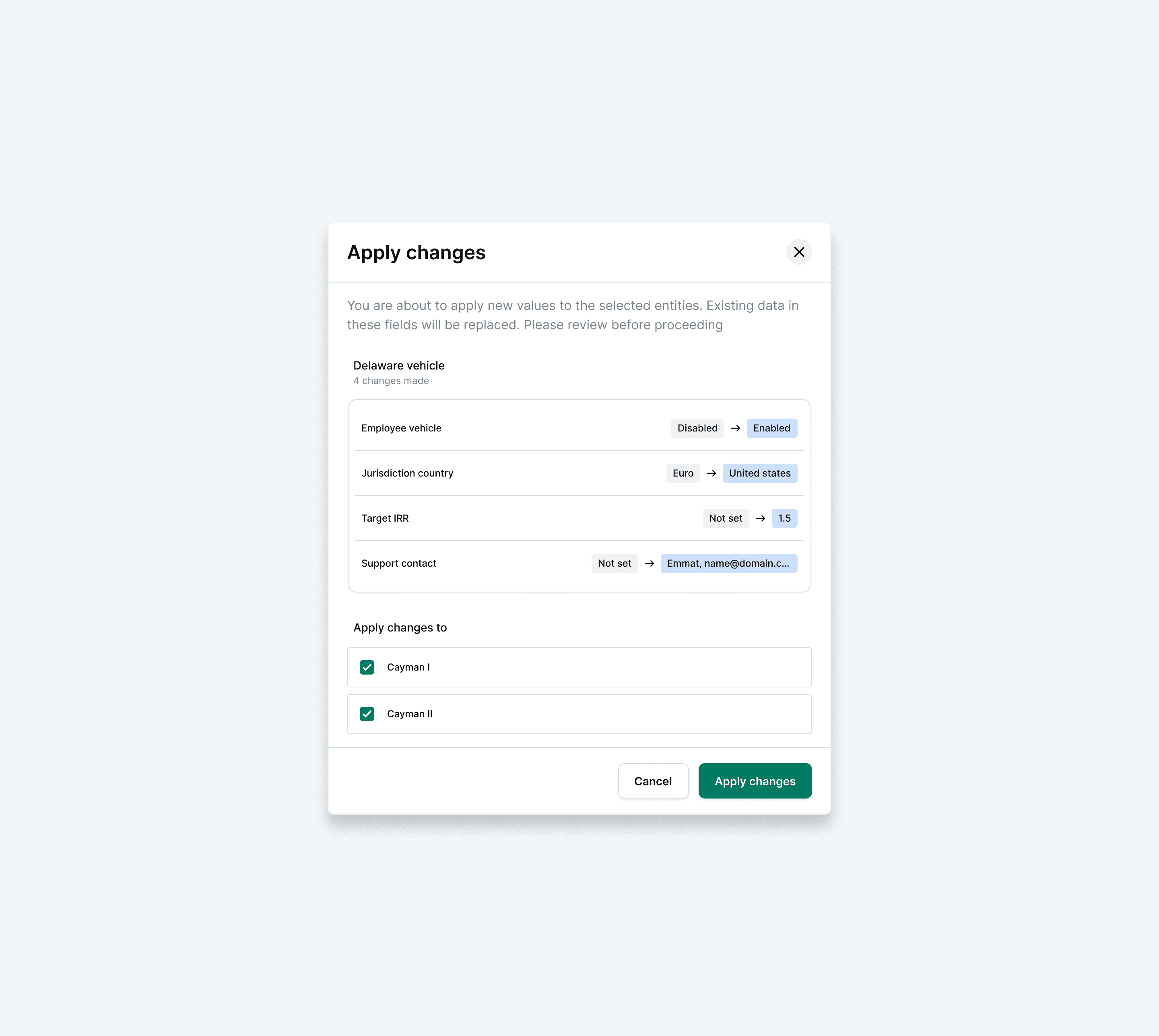
Data parity, not data replication.The new system covers every mandatory field that downstream services currently source from Daphne, so nothing degrades in the switch. But the goal is a best-in-class data model built for Vega's needs, not a 1:1 copy of Daphne's schema.
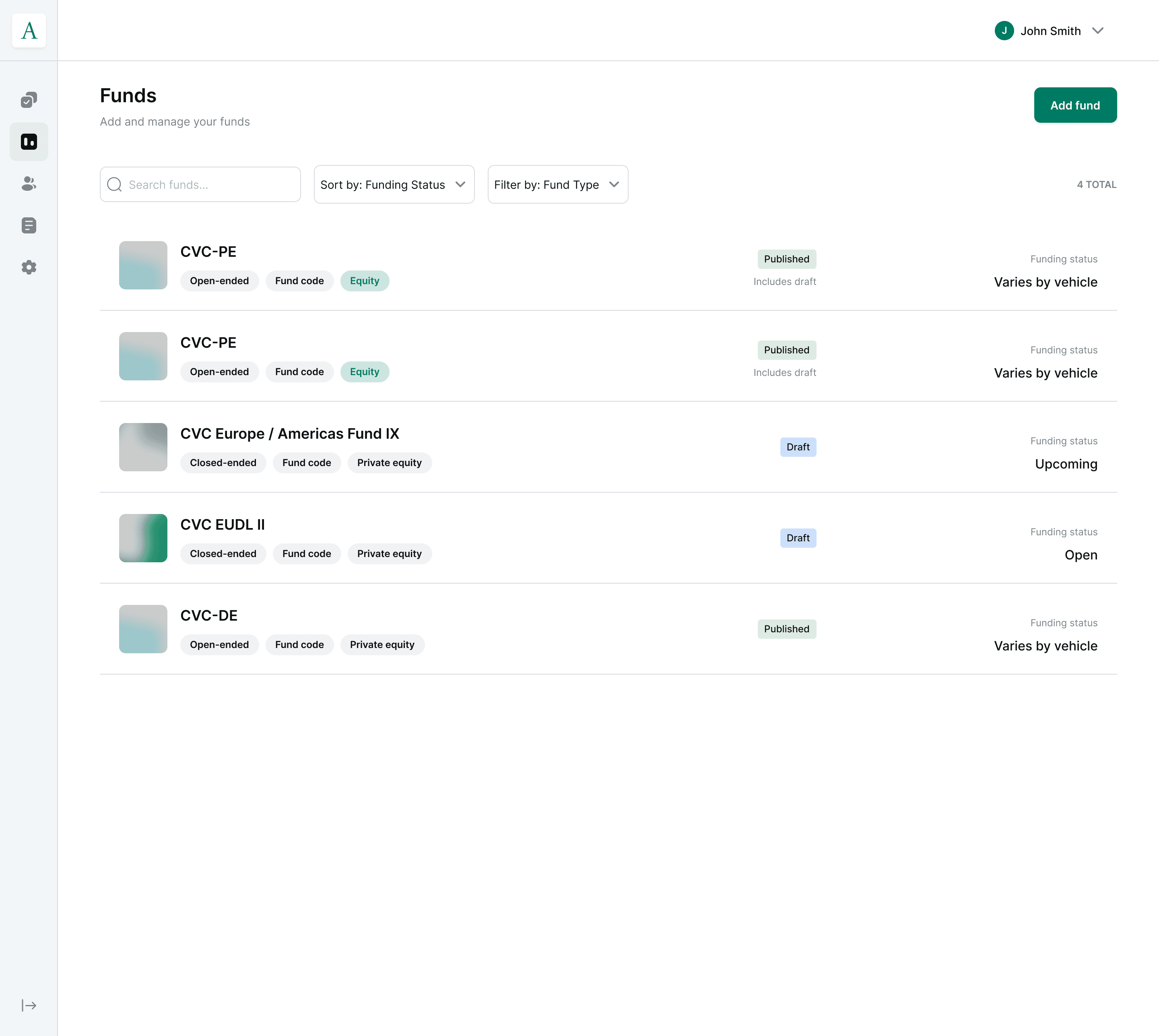
A genuine alternative to Daphne, not a workaround. Once live, Vega should be able to onboard a new GP end-to-end (static product data included) without any Daphne integration at all.
Faster onboarding by design.The current Daphne-dependent workflow is the baseline to beat; ingest → review → publish is built specifically to cut the time and operational effort required to bring a new GP's fund data online.
Results
Since the product master is not yet live, these are the targets it's being built against, not results achieved to date:
- The next GP onboarded after Apollo uses the Vega product master for all product data, with less than 1 day of Vega operational effort required.
- ≥90% positive feedback from pilot GP users on reliability and ease of use, tracked across the first year post-launch via quarterly interviews.
- The Fund Management service(s) support at least 5 additional GPs by end of 2026, scaling horizontally and elastically with load.
This prototype was 100% built with Claude Code and a set of custom skills we wrote. The skills were authored by our lead design engineer George Drury.
Open to new projects and ideas
Building something in AI, finance, or complex workflows? I'd love to hear what you're working on.
Send email